After hearing about Nostr from multiple people over the past weeks I decided to take a look and learn more about it. I found nostr-resources.com, usenostr.org and github.com/aljazceru/awesome-nostr to be helpful to get an initial overview.
Running a nostr relay
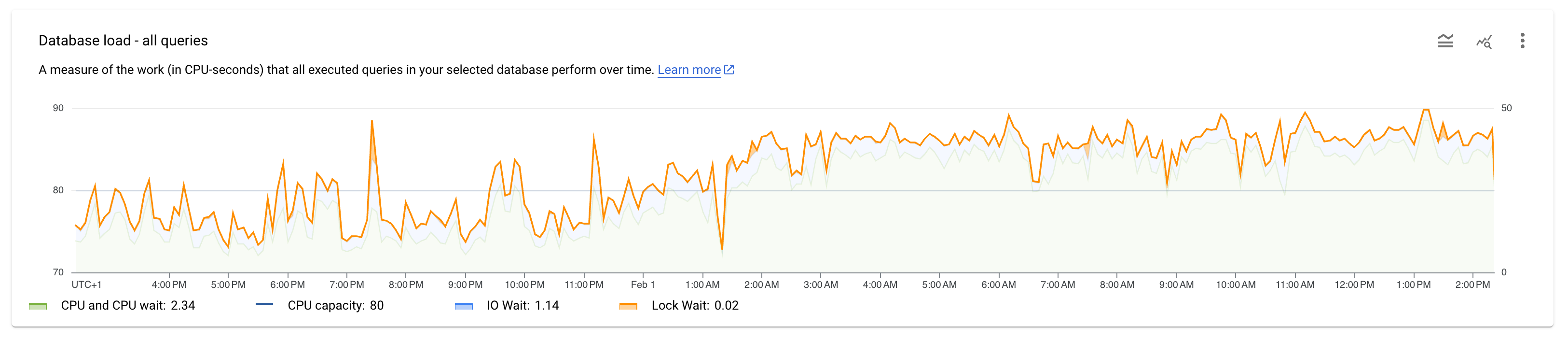
As a next step I looked into setting up my own relay and it’s surprisingly simple. I now have a relay based on github.com/scsibug/nostr-rs-relay running at wss://nostr.notmyhostna.me.
I was looking for a simple Go + Postgres relay project but that doesn't seem to exist yet. This is a fast-moving landscape right now though, so this might be outdated information in a week.
If you are using docker-compose it's a simple as the following snippet, additionally you'll have to configure your reverse proxy (nginx, in my case) to point that container.
nostr:
image: scsibug/nostr-rs-relay:latest
restart: always
ports:
- "7000:8080"
volumes:
- /home/ubuntu/services/nostr/nostr-config/config.toml:/usr/src/app/config.toml
- /home/ubuntu/services/nostr/nostr-data:/usr/src/app/db
The relay starting up and listening to web socket connections:
Feb 07 19:39:39.606 INFO nostr_rs_relay: Starting up from main
Feb 07 19:39:39.607 INFO nostr_rs_relay::server: listening on: 0.0.0.0:8080
Feb 07 19:39:39.610 INFO nostr_rs_relay::repo::sqlite: Built a connection pool "writer" (min=1, max=2)
Feb 07 19:39:39.611 INFO nostr_rs_relay::repo::sqlite: Built a connection pool "maintenance" (min=1, max=2)
Feb 07 19:39:39.612 INFO nostr_rs_relay::repo::sqlite: Built a connection pool "reader" (min=4, max=8)
Feb 07 19:39:39.612 INFO nostr_rs_relay::repo::sqlite_migration: DB version = 0
Feb 07 19:39:39.810 INFO nostr_rs_relay::repo::sqlite_migration: database pragma/schema initialized to v15, and ready
Feb 07 19:39:39.810 INFO nostr_rs_relay::repo::sqlite_migration: All migration scripts completed successfully. Welcome to v15.
Feb 07 19:39:39.811 INFO nostr_rs_relay::server: db writer created
Feb 07 19:39:39.811 INFO nostr_rs_relay::server: control message listener started
Writing my first "post"
I used iris.to to write my first "post". What I found scary is that for all clients you have to use your one-and-only private key as the password to log into your account. I didn't look too much into existing plans to have finer grained "sub-keys" in the future, but I'm sure that's something that's being discussed.
Here's what an event payload looks like, every field is explained in the protocol specification here.
{
"content": "Testing Nostr!",
"created_at": 1675799677,
"id": "e57401dfbe49cd199e60e0b3c4485b96c8286980f07bc9513a66ec21f081d809",
"kind": 1,
"pubkey": "6e5d92642b2a5e03ff59b50ff14b5c54a08ceceb465146985b8ffa3527523c8b",
"sig": "fdf1b3f635cd706b216970c86ec3db35e075369d4feabe64e3789c695bf18dabb2468424aece8885bcad6c8f0aa2d786d055d3c940a2b7da4d5550d6d2555830",
"tags": []
}
Replies to that post will then reference this id in their tags:
{
"created_at": 1675799932,
"pubkey": "fe2d5cf62e95aab419b07b6f8a7b75d3cb3066fae25c6b44ace0f9f30c59303d",
"kind": 1,
"content": "We hear you!",
"sig": "b8313fcc6644fe8cd7841da7e0dcb0381f3155c7b3802fc54d655e60808f29b88c513db3c45c323e6738abf44d96f0e3866893858ae54fc230f971f1c93ca7d9",
"id": "21b120394430ad51188c6fe62632ecb269d41bb5ae9bc6a18a90448e864c6932",
"tags": [
[
"e",
"e57401dfbe49cd199e60e0b3c4485b96c8286980f07bc9513a66ec21f081d809"
],
[
"p",
"6e5d92642b2a5e03ff59b50ff14b5c54a08ceceb465146985b8ffa3527523c8b"
]
]
}
Finding people to follow
The best way I've found so far is nostr.directory. This tool scans people you follow on Twitter and checks if they posted a "proof" tweet to verify their nostr.directory entry.
Current impression
The project is still in a very early stage. It is more confusing than Mastodon for non-technical newcomers but from a technical point of view it's very simple.
The iOS app Damus looks more polished than expected, but is also buggy. I was not able to add my own relay to it, for example. That there's an app at all in the iOS app store at this early stage is a big plus though. It makes giving this a try so much easier.
For now I'll keep an eye on the project and keep my relay running. I'm looking forward to seeing more projects being built on this protocol.
]]>












 ]]>
]]>