What I wish existed for self-hosted databases
Published on Dec 06, 2025
In a recent discussion on HN I've mentioned that self-hosting databases is still a bit of a pain compared to running one on a cloud hoster. Someone asked "why" so I thought I'll just quickly write it down here.
Running something like Postgres on a server is easy. You either install some package and start the service, or you run it in Docker. This is just a small part of the task though, after that you'll have to research the right script for your backup cron jobs and figure out how to get alerted on failed backups. In the future you'll have to figure out how to restore a backup, upgrade your database or see what you have to do to create a read-only standby instance that receives replication events from your main database.
On a cloud hoster this is usually a few clicks away where you just select what kind of database you want and how many resources you think you'll need. You can be certain that backups work and you just have to select which point in time you want to restore to. This is something that, to my knowledge, doesn't exist yet.
There's a project that I've recently found that covers the "backup" use case, including webhooks being sent on successful or failed backups. It's called pgbackweb and seems to work fine so far.
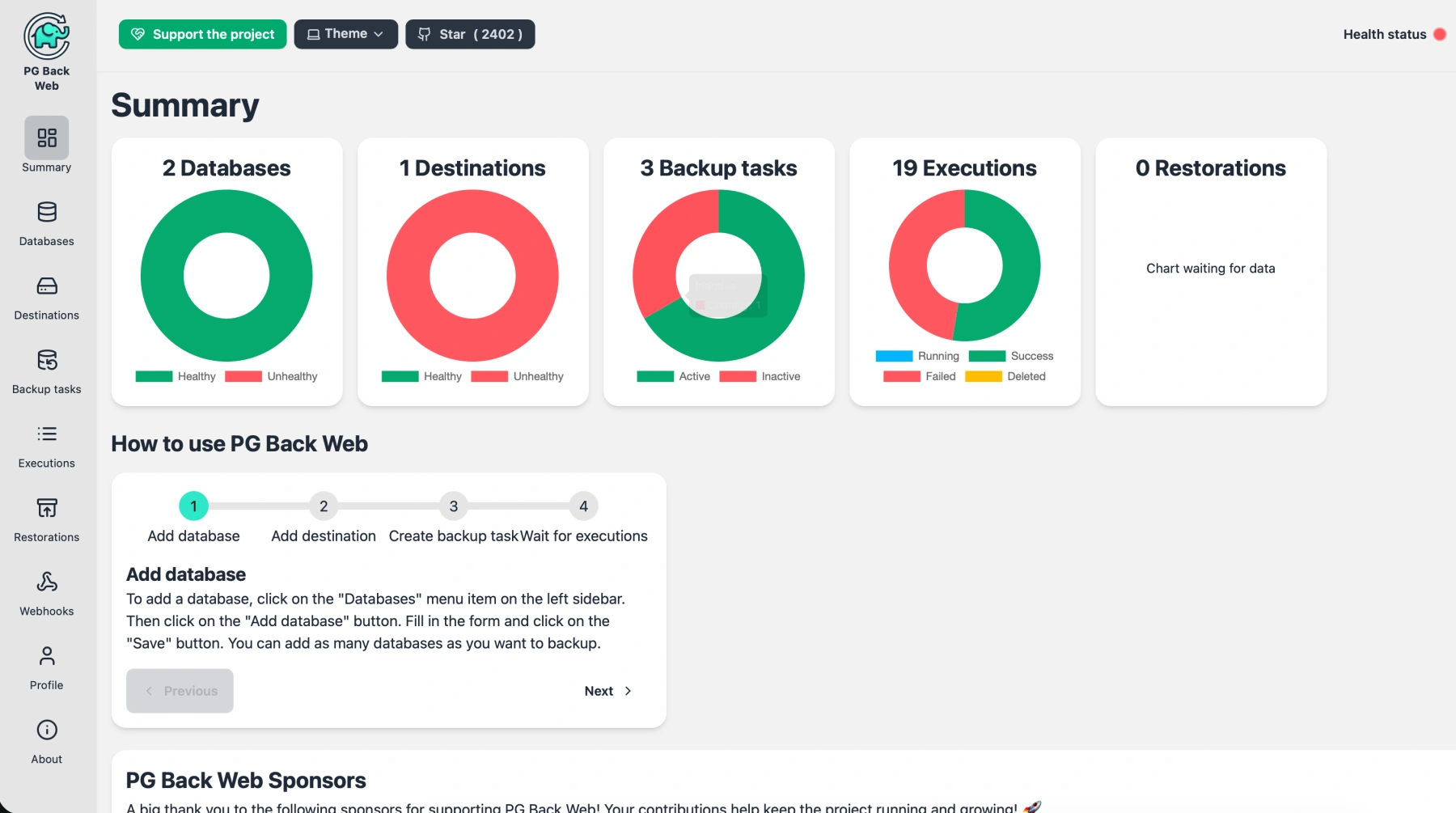
I'm still looking for something that is closer to a cloud provider and includes provisioning, backups and other maintenance tasks like setting up replicas. Ideally it would not be exclusively for Postgres but also include other data stores.